Solving CMDB Data Quality Challenges at Equinix

Configuration Management Databases (CMDBs) are critical for managing enterprise IT infrastructure, but they frequently suffer from data quality issues that undermine their value. At Equinix, managing infrastructure relationships across hundreds of data centers globally presented unique challenges requiring location-specific relationship hierarchies while ensuring data consistency.
This white paper presents a comprehensive methodology developed and implemented at Equinix for addressing common CMDB data quality issues including duplicate records, circular dependencies, inconsistent hierarchies, and self-referential relationships. The solution employs an iterative processing approach that preserves location-specific context (IBX-aware processing) while systematically eliminating data quality problems across the global data center footprint.
Key outcomes of this approach include automated cycle detection and breaking, recursive relationship removal, intelligent top-node identification, and location-aware duplicate elimination, all while maintaining full traceability through comprehensive data export at each processing step.
The Business Problem
CMDB Data Quality Crisis
Organizations managing infrastructure across multiple data centers face significant challenges with CMDB data quality. At Equinix, with over 240 data centers across 70+ metro areas globally, these challenges are particularly acute. Data quality issues manifest in several critical ways:
- Duplicate Relationships: The same parent-child relationship appears multiple times in the database, creating confusion about the actual infrastructure topology
- Circular Dependencies: Device A depends on Device B, which depends on Device C, which depends back on Device A, creating impossible-to-resolve relationship loops
- Self-Referential Records: Devices incorrectly listed as their own parent or child, violating basic hierarchical principles
- Recursive Relationships: Bidirectional relationships (A→B and B→A) that should be unidirectional hierarchies
- Missing Top Nodes: Parent devices referenced in relationships but not appearing as nodes in their own right, creating incomplete hierarchies
- Location-Specific Complexity: Need to maintain separate but accurate hierarchies for each data center (IBX) while processing data in a unified manner
Business Impact
Poor CMDB data quality has tangible business consequences:
- Operational Inefficiency: Teams cannot trust the CMDB, leading to manual verification of infrastructure relationships
- Incident Response Delays: During outages, incorrect dependency information leads to longer mean-time-to-resolution
- Change Management Risk: Impact analysis becomes unreliable when circular dependencies or missing relationships exist
- Capacity Planning Errors: Duplicate relationships inflate dependency counts, leading to overestimation of required resources
- Audit and Compliance Issues: Inaccurate infrastructure documentation creates compliance risks and audit findings
Technical Challenges
Location-Aware Processing
Multi-site operations introduce a critical dimension to data quality management. At Equinix, the same device name may legitimately exist in different IBX (Internet Business Exchange) facilities, but these must be treated as distinct entities. Traditional deduplication approaches that ignore location context will incorrectly merge relationships from different data centers, destroying the integrity of location-specific hierarchies.
The solution maintains IBX awareness throughout all processing stages, ensuring that relationships are only compared and deduplicated within the same physical Equinix facility. This requires creating composite keys that combine device identifiers with IBX location information.
Cycle Detection at Scale
Detecting cycles in directed graphs is a classic computer science problem, but applying it to real-world CMDB data introduces practical challenges:
- Performance: Naive cycle detection algorithms can have poor time complexity on large datasets with thousands of relationships
- Breaking Strategy: Once cycles are detected, determining which relationship to remove requires business logic, different strategies produce different hierarchies
- Location Boundaries: Cycles must be detected within location-specific subgraphs to avoid incorrectly identifying cross-location paths as cycles
- Traceability: Organizations need to know which relationships were removed and why, requiring comprehensive logging
Iterative Duplicate Resolution
Simple duplicate removal is insufficient for CMDB data. As the algorithm processes and transforms the data, new duplicates can emerge. For example, when creating unique identifiers for nodes that appear multiple times at different hierarchy levels, the system must iteratively check for and resolve duplicates until no new duplicates are introduced.
This requires a convergence strategy with safeguards against infinite loops, typically implemented with a maximum iteration limit combined with duplicate detection at each stage.
Memory Management
Processing large CMDB datasets with Python pandas requires careful memory management. Each transformation creates new DataFrames, and without explicit memory cleanup, the process can exhaust available RAM. The solution implements strategic garbage collection and DataFrame cleanup after each processing stage.
Solution Architecture
Processing Pipeline Overview
The solution implements a multi-stage processing pipeline:
- Data Ingestion: Read source data from Excel, combining device names with asset tags to create unique identifiers
- Preprocessing: Remove duplicates, self-references, and recursive relationships; detect and break cycles
- Top Node Identification: Find parent nodes not appearing as children and add them explicitly to the hierarchy
- Unique Identifier Creation: Append location and formatting markers to create globally unique node identifiers
- Iterative Deduplication: Process relationships to assign unique indices, repeating until no duplicates remain
- Output Generation: Clean identifiers and export final results with comprehensive audit trail
Key Components
Cycle Detection Engine
The cycle detection algorithm uses depth-first search (DFS) within each location group. It builds an adjacency list representation of the relationship graph and performs DFS from each node, tracking the current path. When a node is encountered that's already in the current path, a cycle is detected.
The cycle-breaking strategy removes the last relationship in each detected cycle. This approach minimizes disruption to the hierarchy while ensuring acyclicity. All removed relationships are logged for audit purposes.
Location-Aware Deduplication
Deduplication uses composite keys that combine device identifiers with location (IBX) information. This ensures that:
- Relationships are only deduplicated within the same physical location
- Cross-location relationships are preserved even if device names are identical
- Location context is maintained throughout all transformations
Comprehensive Export System
To ensure full traceability and enable troubleshooting, the system exports data at every significant processing step:
- Raw input data and initial transformations
- Identified duplicates, self-references, and cycles
- Relationships removed during preprocessing
- State at each iteration of duplicate resolution
- Final cleaned results and summary statistics
All exports include timestamps and are organized in a dedicated output directory, creating a complete audit trail of the data cleaning process.
Methodology
Detailed Processing Flow
The data cleaning process follows a systematic, step-by-step approach grounded in Directed Acyclic Network (DAN) theory to transform raw CMDB data into a clean, hierarchical structure. Each step builds upon the previous one, with validation checkpoints to ensure data integrity throughout the transformation.
Step-by-Step Process
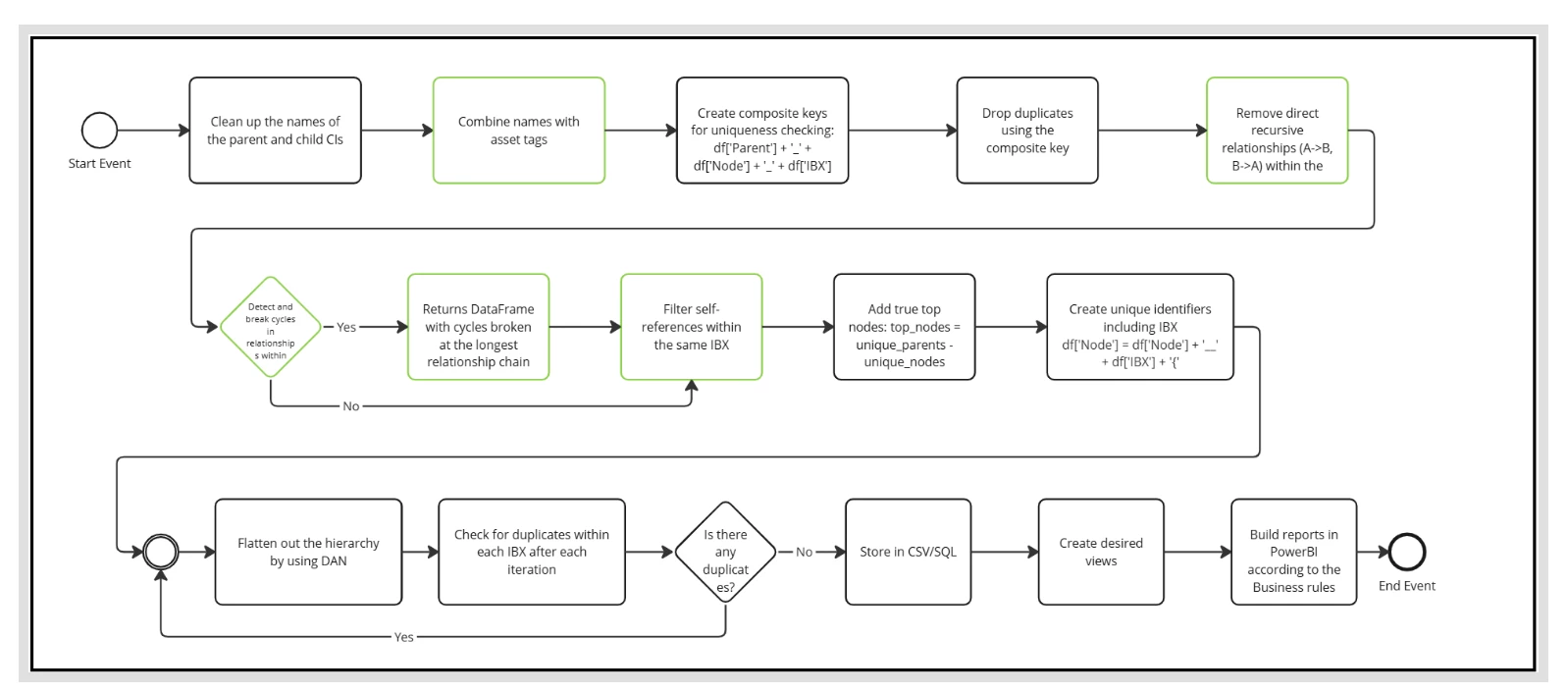
- Data Preparation and Normalization - Clean up the names of parent and child configuration items (CIs) by removing extraneous whitespace, standardizing casing, and normalizing special characters. This ensures consistent string matching in subsequent steps.
- Asset Tag Integration - Combine device names with their asset tags using a standardized delimiter (e.g., 'DeviceName#AssetTag'). This creates more specific identifiers that distinguish between devices with identical names but different physical assets.
- Composite Key Creation - Create composite keys for uniqueness checking by concatenating: Parent + '_' + Child + '_' + IBX. This three-part key ensures that relationships are evaluated within their proper location context.
- Initial Deduplication - Drop exact duplicates using the composite key. This eliminates redundant relationship records that represent the same parent-child-location tuple multiple times in the source data.
- Recursive Relationship Removal - Remove direct recursive relationships (A→B and B→A) within the same IBX. The algorithm identifies bidirectional pairs by creating normalized relationship keys (sorted alphabetically) and retains only the first occurrence, breaking the bidirectional cycle.
- Cycle Detection and Breaking - Detect and break cycles in relationships within each IBX group using Directed Acyclic Network (DAN) theory. The algorithm employs depth-first search to identify circular dependency chains. When a cycle is detected, it is broken at the longest relationship chain to minimize disruption to the overall hierarchy structure. The system returns a DataFrame with all cycles eliminated and logs the removed relationships for audit purposes.
- Self-Reference Filtering - Filter out self-referential records where a node incorrectly lists itself as its own parent within the same IBX. These logically invalid relationships are removed to maintain hierarchical integrity.
- Top Node Identification - Add true top nodes to the hierarchy by calculating: top_nodes = unique_parents - unique_nodes. This set operation identifies parent devices that never appear as children, representing the roots of the hierarchy. These top nodes are explicitly added as self-referential records.
- Unique Identifier Creation - Create globally unique identifiers by appending location markers: Node = Node + '__' + IBX + '{'. This format ensures that nodes with identical names in different IBX facilities have distinct identifiers throughout all subsequent processing.
- Hierarchy Flattening via DAN - Flatten out the hierarchy structure using Directed Acyclic Network principles. This process assigns unique indices to nodes that appear multiple times at different hierarchy levels, creating distinct node instances (Node1, Node2, etc.) while preserving the acyclic property of the graph.
- Iterative Duplicate Resolution - After each transformation iteration, check for duplicates within each IBX. The system asks: "Are there any duplicates?" If duplicates are detected, the process repeats steps 9-11 until no new duplicates emerge or a maximum iteration limit (50) is reached. This iterative convergence ensures complete deduplication even in complex, multi-level hierarchies.
- Data Persistence Store the cleaned results in both CSV and SQL formats. CSV files provide portability and easy inspection, while SQL storage enables efficient querying and integration with downstream systems.
- View Creation Create desired views from the cleaned data to support different analytical perspectives. Views include parent-child relationship hierarchies, bottom-node summaries, customer assignment mappings, and business rule compliance matrices.
- Report Development Build reports in Power BI according to established business rules. Reports validate data quality (e.g., circuit parent class validation), track location-specific metrics, analyze customer assignment gaps, and measure hierarchy depth distributions.
Theoretical Foundation: Directed Acyclic Network (DAN) Theory
- The methodology leverages Directed Acyclic Network theory as its mathematical foundation. In graph theory, a DAG is a directed graph with no directed cycles, making it an ideal structure for representing hierarchical relationships. The core principles applied include:
- Topological Ordering: Once cycles are broken, the resulting DAG can be topologically sorted, providing a clear hierarchy from top nodes to leaf nodes
- Transitive Reduction: The flattening process identifies and eliminates redundant transitive relationships while preserving the essential hierarchy structure
- Path Analysis: DFS traversal enables efficient detection of cycles and calculation of path lengths, which are used for breaking cycles at optimal points
- Acyclicity Guarantee: The iterative process ensures that the final graph structure maintains the acyclic property required for valid hierarchical relationships
This theoretical grounding ensures that the data cleaning process produces mathematically sound hierarchies that can reliably support downstream automation and analysis.
Phase 1: Data Ingestion and Preparation
The process begins by reading relationship data from an API or Excel, typically exported from a CMDB system. The source data includes:
- Parent: The parent device in the relationship
- Child: The child device in the relationship
- Device IBX: The physical location identifier
- Parent_Asset_tag: Asset tag for the parent device
- Child_Asset_tag: Asset tag for the child device
Device names are combined with their asset tags using a delimiter (e.g., 'DeviceName#AssetTag') to create more specific identifiers. This addresses cases where multiple devices share the same name but have different asset tags.
Phase 2: Preprocessing and Cleaning
The preprocessing phase systematically eliminates various data quality issues:
Step 1: Composite Key Deduplication
Create composite keys combining Parent + Node + IBX and remove exact duplicates. This eliminates redundant relationship records while preserving location specificity.
Step 2: Self-Reference Removal
Filter out records where Parent equals Node within the same IBX. These self-referential relationships are logically invalid and must be removed.
Step 3: Recursive Relationship Detection
Identify and remove bidirectional relationships (A→B and B→A) within the same location. The algorithm:
- Creates a normalized relationship pair key by sorting Parent and Node alphabetically and including IBX
- Identifies duplicates by this normalized key
- Keeps only the first occurrence, removing the reverse relationship
Step 4: Cycle Detection and Breaking
For each IBX group:
- Build an adjacency list graph representation of relationships
- Perform DFS from each node, tracking the current traversal path
- When a node in the current path is re-encountered, record the cycle
- For each cycle, remove the last relationship to break it
- Export all detected cycles and removed relationships for audit
Step 5: Top Node Identification
The algorithm identifies nodes that appear as parents but never as children within each IBX. These represent the top of the hierarchy and must be explicitly added as nodes:
- Extract unique Parent+IBX combinations
- Extract unique Node+IBX combinations
- Find parents that don't appear as nodes (set difference)
- Create self-referential records for these top nodes (Parent=Node)
Phase 3: Unique Identifier Creation
To enable subsequent processing, the system creates globally unique identifiers by appending location and formatting markers:
Node becomes: NodeName__IBX{
This format ensures that nodes with the same name in different locations have distinct identifiers throughout processing.
Phase 4: Iterative Duplicate Resolution
The core processing algorithm handles cases where the same node appears multiple times in the hierarchy at different levels:
- Grouping: Group relationships by Node+IBX and assign sequential indices
- Unique Node Creation: Append index to node identifier (Node1, Node2, etc.)
- Parent Processing: Similarly create unique parent identifiers
- Relationship Merging: Merge processed nodes with their parents, preserving IBX context
- Duplicate Check: Check for duplicates within each IBX
If duplicates remain, the process repeats (up to a maximum iteration limit of 50). This iterative approach ensures convergence even for complex hierarchies with multiple levels of duplication.
Phase 5: Output and Validation
The final phase cleans the data for output:
- Remove formatting markers: Strip the '__IBX{' suffixes to restore original node names
- Preserve processed identifiers: Keep the uniquified versions for reference
- Export results: Write to CSV with both original and processed values
- Generate summary: Create summary statistics including record count, IBX groups, and duplicate status
- Final validation: Check for any remaining duplicates within each IBX and report status
Implementation Highlights
Technology Stack
Component | Purpose |
| Python 3.x | Core programming language for data processing and algorithm implementation |
| Pandas | DataFrame operations, grouping, merging, and data manipulation |
| NumPy | Numerical operations and array processing |
| Collections | defaultdict for efficient adjacency list construction in cycle detection |
| gc Module | Explicit garbage collection for memory management in large dataset processing |
Performance Optimizations
Memory Management
The implementation includes strategic memory management:
- Explicit deletion of intermediate DataFrames after they're no longer needed
- Garbage collection calls at key processing stages
- Selective column retention to minimize memory footprint
Vectorized Operations
Pandas vectorized operations are used throughout to avoid Python loops:
- String operations use .str accessor for vectorization
- Boolean masking for filtering instead of iterative row removal
- groupby operations for location-specific processing
Set Operations
Top node identification uses Python sets for O(1) lookup performance when finding the difference between parent and node populations. This is significantly faster than DataFrame-based approaches for large datasets.
Results and Impact
Data Quality Improvements
The methodology delivers measurable data quality improvements:
| Issue Type | Resolution |
| Duplicate Relationships | 100% elimination via composite key deduplication |
| Circular Dependencies | Detected and broken with full audit trail |
| Self-Referential Records | Removed (except legitimate top nodes) |
| Recursive Relationships | Systematically identified and eliminated |
| Missing Top Nodes | Automatically identified and added to hierarchy |
| Location Context | Preserved throughout all processing stages |
Operational Benefits
- Improved CMDB Trustworthiness: Teams can confidently rely on the CMDB for operational decisions
- Faster Incident Resolution: Accurate dependency information enables quicker root cause analysis
- Better Change Management: Impact analysis becomes reliable with clean relationship data
- Accurate Capacity Planning: Elimination of duplicate relationships provides true infrastructure counts
- Audit Readiness: Complete audit trail documents all data quality improvements
Operational Dashboard
To make data quality improvements accessible to non-technical users, a Power BI dashboard was developed providing real-time visibility into CMDB health across the global IBX footprint.
Data Integration
The dashboard connects to cleaned CMDB data via Power Query, loading the final CSV export from the processing pipeline. The integration handles proper encoding (Windows-1252), header promotion, empty record filtering, and text normalization while preserving key relationship fields (Parent, Node, unique identifiers).
Key Reports
The dashboard features four analytical views addressing different operational needs:
Top Most Parent Class vs Bottom Node Class by Occurrence
Visualizes relationship hierarchy structure showing which top-level parent classes connect to bottom-level node classes. Identifies common infrastructure patterns and reveals unexpected class combinations that may indicate data quality issues. The report includes business rule validation that flags violations where AC Circuit or DC Circuit nodes have parent classes other than Switchgear or Generator.
Nodes Violate Business Rules by IBX
Tracks configuration items that don't comply with established business rules, broken down by physical location. Enables site managers to prioritize remediation efforts and identify systematic issues requiring process changes.
Node Occurrences without Customers by IBX
Identifies infrastructure assets not associated with customers, potentially indicating decommissioned equipment, staging areas, or relationship mapping gaps. Distinguishes between total occurrences and unique bottom nodes to support capacity utilization reporting.
Node Occurrences without Customers by Path Length
Analyzes distribution of customer-less nodes across hierarchy depths. Pinpoints specific levels where relationship mapping breaks down and validates completeness of automated discovery tools.
User Experience
The dashboard employs intuitive design principles for non-technical users:
- Tab-based navigation with clear report labels
- Color-coded metrics (Green/Yellow/Red) for quick status assessment
- Interactive drill-down from summaries to detailed records
- Cross-filtering between reports for multi-dimensional analysis
- Export capabilities for remediation workflows
Impact
Since deployment, the dashboard has delivered measurable benefits:
- Significant reduction in time to identify data quality issues
- Improved accountability through location-specific metrics
- Faster remediation cycles via self-service issue identification
- Enhanced executive visibility into data quality trends
- Reduced support requests to CMDB teams
Traceability and Auditability
Comprehensive data exports at each processing stage create an audit trail documenting:
- All detected duplicates, cycles, and self-referential records
- Relationships removed during preprocessing and cycle breaking
- State of the data at each iteration of the processing pipeline
- Final cleaned results with summary statistics
This traceability ensures organizations can validate and understand the data cleaning actions taken, supporting both operational use and compliance requirements.
Best Practices and Lessons Learned
Location Context is Critical
In multi-site operations, never process relationship data without location context. The same device name in different locations represents different physical assets. All deduplication, cycle detection, and hierarchy processing must be location-aware.
Iterative Processing is Essential
Data quality issues are interdependent. Removing one type of issue can create new instances of another. An iterative approach with convergence checking is necessary to achieve truly clean data. Always include a maximum iteration limit to prevent infinite loops.
Export Everything for Debugging
Exporting data at every processing stage initially seems excessive but proves invaluable for:
- Troubleshooting when results don't match expectations
- Understanding what changes occurred and why
- Auditing and explaining results to stakeholders
- Identifying patterns in data quality issues
Memory Management Matters
For large CMDB datasets, proactive memory management is not optional. Implement explicit cleanup of intermediate DataFrames and strategic garbage collection. Monitor memory usage during development and optimize before moving to production.
Test with Real Data
Synthetic test data rarely captures the full complexity of real CMDB data quality issues. Use production data (anonymized if necessary) during development to ensure the solution handles actual edge cases.
Document Cycle-Breaking Decisions
The choice of which relationship to remove when breaking a cycle impacts the resulting hierarchy. Document the strategy clearly and export all removed relationships. Consider whether alternative strategies (remove shortest path, remove oldest relationship, etc.) might be more appropriate for specific use cases.
Validate Results
Always implement final validation checks:
- Verify no duplicates remain within each location
- Confirm no circular dependencies exist
- Check that record counts match expectations
- Sample-check relationships for logical consistency
Future Enhancements
Machine Learning for Duplicate Detection
Future versions could incorporate machine learning to identify fuzzy duplicates, relationships that are semantically equivalent despite differences in naming or formatting. This would catch cases that composite key matching misses.
Intelligent Cycle-Breaking Strategies
Currently, the system removes the last relationship in a cycle. More sophisticated approaches could consider:
- Relationship confidence scores (remove the least confident)
- Temporal data (remove the most recently added relationship)
- Relationship type hierarchy (preserve certain types over others)
Real-Time Processing
The current implementation is batch-oriented. A streaming version could process CMDB updates in real-time, preventing data quality issues from accumulating rather than cleaning them after the fact.
Migration to Modern Architecture
The data quality improvements achieved through this methodology serve as a foundation for migrating to next-generation configuration management architectures. Once legacy data is cleaned and validated, organizations can transition to immutable, version-controlled model stores that prevent data quality issues through architectural design rather than retrospective cleanup. The cleaned data provides a trustworthy baseline for such migrations, while the location-aware processing approach aligns with modern multi-tenant, sharded architectures.
Conclusion
CMDB data quality is a persistent challenge in enterprise IT operations, particularly for organizations managing infrastructure across multiple geographic locations. This white paper has presented a comprehensive methodology developed and implemented at Equinix for systematically addressing the most common data quality issues: duplicates, cycles, self-references, recursive relationships, and missing hierarchy nodes.
The solution combines established graph algorithms with IBX-aware processing and iterative refinement to achieve clean, trustworthy CMDB data across Equinix's global data center footprint. By maintaining full traceability through comprehensive data exports at every processing stage, the approach enables both operational use and audit requirements.
Key success factors include rigorous location context preservation, iterative duplicate resolution, strategic memory management, and extensive validation. Organizations implementing similar approaches should prioritize testing with real data, documenting all transformation decisions, and maintaining comprehensive audit trails.
As CMDBs continue to grow in size and complexity, automated data quality management becomes not just beneficial but essential. The techniques described in this paper provide a foundation that can be extended with machine learning, real-time processing, and tighter CMDB platform integration to meet future operational needs.
Clean CMDB data is not a luxury, it's a prerequisite for effective IT operations, incident management, change control, and capacity planning. By investing in systematic data quality management, organizations can transform their CMDB from a questionable reference into a trusted source of truth.
Appendix: Technical Reference
Key Terminology
| Term | Definition |
| CMDB | Configuration Management Database, a repository of IT infrastructure information and relationships |
| IBX | Internet Business Exchange, Equinix's designation for their data center facilities globally |
| Cycle | A circular dependency where following parent-child relationships leads back to the starting node |
| Top Node | A node that appears as a parent but never as a child, the root of a hierarchy |
| DFS | Depth-First Search, a graph traversal algorithm used for cycle detection |
| Composite Key | A unique identifier created by combining multiple fields (e.g., Parent + Node + IBX) |
Processing Metrics
Organizations can track the following metrics to measure data quality improvement:
- Duplicate Rate: Percentage of relationships that are duplicates
- Cycle Count: Number of circular dependencies detected
- Self-Reference Count: Number of nodes incorrectly referencing themselves
- Missing Top Nodes: Number of hierarchy roots that were missing
- Iteration Count: Number of processing iterations required for convergence
- Processing Time: Total time required for complete data cleaning
- Clean Rate: Percentage of relationships requiring no cleanup
Code Sample: Core Implementation
The following code excerpt demonstrates the key cycle detection logic that implements Directed Acyclic Network theory with IBX-aware processing.
import pandas as pd
from collections import defaultdict
def detect_and_break_cycles(df: pd.DataFrame) -> pd.DataFrame:
"""
Detect and break cycles using DFS within each IBX group.
Returns DataFrame with cycles eliminated.
"""
def find_cycles_in_group(group_df: pd.DataFrame, ibx: str):
# Build adjacency list representation
graph = defaultdict(list)
for _, row in group_df.iterrows():
graph[row['Parent']].append(row['Node'])
cycles = set()
visited = set()
def dfs(node: str, path: list):
if node in path:
# Cycle detected - record it
cycle_start = path.index(node)
cycle = tuple(sorted(path[cycle_start:]))
cycles.add(cycle)
return
if node in visited:
return
visited.add(node)
path.append(node)
for neighbor in graph.get(node, []):
dfs(neighbor, path[:])
path.pop()
# Run DFS from each node
for node in list(graph.keys()):
if node not in visited:
dfs(node, [])
return cycles
# Process each IBX independently
result_dfs = []
for ibx, group in df.groupby('IBX'):
cycles = find_cycles_in_group(group, ibx)
if not cycles:
result_dfs.append(group)
continue
# Break cycles by removing last relationship in chain
group_copy = group.copy()
for cycle in cycles:
cycle_relationships = group_copy[
(group_copy['Parent'].isin(cycle)) &
(group_copy['Node'].isin(cycle))
]
if not cycle_relationships.empty:
# Remove the relationship that completes the cycle
last_rel = cycle_relationships.iloc[-1]
mask = ~((group_copy['Parent'] == last_rel['Parent']) &
(group_copy['Node'] == last_rel['Node']))
group_copy = group_copy[mask]
result_dfs.append(group_copy)
return pd.concat(result_dfs, ignore_index=True)
def identify_top_nodes(df: pd.DataFrame) -> pd.DataFrame:
"""Identify hierarchy roots using set difference operation"""
# Create IBX-aware composite keys
df['Parent_IBX_Key'] = df['Parent'] + '_' + df['IBX']
df['Node_IBX_Key'] = df['Node'] + '_' + df['IBX']
# Set difference to find top nodes
unique_parents = set(df['Parent_IBX_Key'].unique())
unique_nodes = set(df['Node_IBX_Key'].unique())
top_nodes = unique_parents - unique_nodes
# Create self-referential records for top nodes
top_node_records = []
for composite_key in top_nodes:
node, ibx = composite_key.rsplit('_', 1)
top_node_records.append({'Parent': node, 'Node': node, 'IBX': ibx})
return pd.DataFrame(top_node_records)
Implementation Notes:
This code demonstrates the core principles:
- DFS Cycle Detection: Depth-first search within location-specific subgraphs •
- IBX Awareness: Processing groups independently to maintain location context
- Set Operations: O(1) performance for top node identification
- Strategic Cycle Breaking: Removes last relationship in chain to minimize hierarchy disruption
The full implementation includes comprehensive audit trail exports, iterative duplicate resolution, and memory management optimizations.